OI(Olympiad in Informatics,信息学奥林匹克竞赛)是一门新鲜的竞赛学科 。它和和物理、数学等竞赛性质相同。OI也是高考中唯一没有的竞赛学科(虽然我认为以后会加入 )。那么问题来了,我们为什么要学习OI呢?
学习OI,在很大程度上不是为了开发产品,但事实上,开发产品的时候往往离不开OI中所涉及的算法。所以,如果想将来做软件业务的同学也需要学习OI。那么,到底什么是算法竞赛,什么是算法呢?
算法(Algorithm),是算法竞赛的核心 。程序中充斥着算法,生活中充斥着算法,数学里也充斥着算法。我们用下面的例题来讲解一下算法的妙处。
给定一个正整数n n n 1 2 + 2 2 + 3 2 + … … + n 2 1^2+2^2+3^2+……+n^2 1 2 + 2 2 + 3 2 + … … + n 2
这道题,也许许多同学都会想到一个解法:暴力求解法 。也就是,我把n n n y = f ( n ) = ∑ k = 1 n k 2 y=f(n)=\sum_{k=1}^{n}k^2 y = f ( n ) = ∑ k = 1 n k 2 n = 1 0 5 n=10^5 n = 1 0 5
通过对数学公式的推导。我们可以得到y = f ( n ) = ∑ k = 1 n k 2 = n ( n + 1 ) ( 2 n + 1 ) 6 y=f(n)=\sum_{k=1}^{n}k^2=\frac{n(n+1)(2n+1)}{6} y = f ( n ) = ∑ k = 1 n k 2 = 6 n ( n + 1 ) ( 2 n + 1 ) n n n 平方和公式的推导过程 :
前提条件:a 2 + b 2 = a ( a + b ) − b ( a − b ) a^2+b^2=a(a+b)-b(a-b) a 2 + b 2 = a ( a + b ) − b ( a − b )
设S = 1 2 + 2 2 + 3 2 + ⋯ + n 2 S=1^2+2^2+3^2+\dots+n^2 S = 1 2 + 2 2 + 3 2 + ⋯ + n 2
S = 1 ( 2 − 1 ) + 2 ( 3 − 1 ) + ⋯ + n ( n + 1 − 1 ) S=1(2-1)+2(3-1)+\dots+n(n+1-1) S = 1 ( 2 − 1 ) + 2 ( 3 − 1 ) + ⋯ + n ( n + 1 − 1 )
S = 1 ⋅ 2 + 2 ⋅ 3 + ⋯ + n ( n − 1 ) − n ( n + 1 ) 2 S=1·2+2·3+\dots+n(n-1)-\frac{n(n+1)}{2} S = 1 ⋅ 2 + 2 ⋅ 3 + ⋯ + n ( n − 1 ) − 2 n ( n + 1 )
∵ n ( n + 1 ) 2 = 1 3 [ n ( n + 1 ) ( n + 2 ) − ( n − 1 ) n ( n + 1 ) ] ∵\frac{n(n+1)}{2}=\frac{1}{3}[n(n+1)(n+2)-(n-1)n(n+1)] ∵ 2 n ( n + 1 ) = 3 1 [ n ( n + 1 ) ( n + 2 ) − ( n − 1 ) n ( n + 1 ) ]
∴ S = 1 3 ( 1 × 2 × 3 − 0 × 1 × 2 ) + 1 3 ( 2 × 3 × 4 − 1 × 2 × 3 ) + ⋯ + 1 3 [ n × ( n + 1 ) × ( n + 2 ) ∴S=\frac{1}{3}(1\times2\times3-0\times1\times2)+\frac{1}{3}(2\times3\times4-1\times2\times3)+\dots+\frac{1}{3}[n\times(n+1)\times(n+2) ∴ S = 3 1 ( 1 × 2 × 3 − 0 × 1 × 2 ) + 3 1 ( 2 × 3 × 4 − 1 × 2 × 3 ) + ⋯ + 3 1 [ n × ( n + 1 ) × ( n + 2 )
− ( n − 1 ) × n × ( n + 1 ) ] -(n-1)\times n\times(n+1)] − ( n − 1 ) × n × ( n + 1 ) ]
∴ S = n ( n + 1 ) ( 2 n + 1 ) 6 ∴S=\frac{n(n+1)(2n+1)}{6} ∴ S = 6 n ( n + 1 ) ( 2 n + 1 )
看到了吧?这就是算法的伟大。这也给了我们一些启示:
优秀的算法可以帮助我们减少工作量 OI与数学是密不可分的亲兄弟 公式不是无缘无故产生的,而是推导出来的!
具体衡量算法的优秀程度的知识会在后面详细讲解。大家现在需要知道的是,算法是有优劣之分的!
上面的那个例子,仅仅是对式子的恒等变形来优化常数。然而,在一般的算法设计中,我们还需要其他的算法设计策略。
当然,学习并积极地参加到OI中是有很大的好处的。我简单地列举几点:
锻炼思维,开拓视野。
有利于升学。
更高效率地使用电脑。
可以提升你的数学能力和英语能力。
现代的互联网公司在面试的时候更加爱考察程序员的算法素养。因此今天学习OI,对将来想在计算机行业就业的同学也是非常有帮助的。
OI虽然是是一门新起的奥林匹克事业,但是关于OI的国内外赛事是很多的。如果希望通过参加这些比赛来获得荣誉,了解这些比赛是非常有必要的。
NOIP(National Olympiad in Informatics in Provinces,全国青少年信息学奥林匹克联赛),旧称分区联赛 ,是一项由CCF(China Computer Federation,中国计算机学会)承办的全国统一的OI赛事。NOIP分初赛和复赛——初赛是地级市一级的,为笔试,复赛是省与直辖市一级的,为上机。初赛一般在每年十月中旬举行,而复赛一般在每年十一月举行。NOIP支持的语言有C语言 ,C++语言 和Pascal语言 (在2020年,NOIP将不再支持Pascal语言)。为了顺应时代发展的潮流,本套讲义将由C语言和C++语言作为程序描述语言 。
NOIP分普及组和提高组。普及组的难度较低,面向广大的小学生和初中生;提高组的难度较高,面向广大的高中生。NOIP在初赛和复赛都设置了等级奖励制度 ,即一二三等奖颁奖制度。一般来说,进入复赛的资格就是初赛一等奖。不同的省的分数线一般都不一样,浙江江苏的分数线尤其高 ,因此浙江和江苏的OIer需要付出更大的努力才可以获得NOIP的成功。
**NOI(National Olympiad in Informatics,全国青少年信息学奥林匹克竞赛)**是NOIP的兄弟比赛,是一项由CCF(China Computer Federation,中国计算机学会)承办的全国统一的OI赛事。NOI是国内包括港澳在内的省级代表队最高水平的大赛,自1984年至2018年,在国内包括香港、澳门,已组织了33次竞赛活动。每年经各省选拔产生5名选手(其中至少有一名是女选手) ,由中国计算机学会在计算机普及较好的城市组织进行比赛。这一竞赛记个人成绩,同时记团体总分。
NOI期间,举办同步夏令营和NOI网上同步赛,给那些程序设计爱好者和高手提供机会。为增加竞赛的竞争性、对抗性和趣味性以及可视化,NOI组织进行团体对抗赛,团体对抗赛实质上是程序对抗赛,其成绩纳入总分计算。
NOI将从正式选手中选出成绩前50名,作为中国国家集训队,集训队队员将获得清华北大的保送资格。
其他比较著名的OI赛事还有APIO,CTSC,IOI 等。感兴趣的同学可以自行上网搜索。
我们来稍微的了解一下什么是OJ(Online Judge )。OJ是很好的在线OI学习平台,它的中文名字叫做在线测评系统 。OJ上面有许多信息竞赛的习题,我们通过做这些习题来提升自我——最后到达一种神犇的境界。我们主要使用下面的几个OJ:
我主要是想讲一些OJ上面的测评信息的含义:
类型
全写
含义
AC
Accept
程序通过,得到分数
CE
Compile Error
编译错误,失去全部分数
PC
Partially Correct
部分正确,没有分数
WA
Wrong Answer
答案错误,没有分数
RE
Runtime Error
运行时错误,没有分数
TLE
Time Limit Exceeded
超出时间限制,没有分数
MLE
Memory Limit Exceeded
超出内存限制,没有分数
OLE
Output Limit Exceeded
输出超过限制,没有分数
UKE
Unknown Error
出现未知错误,没有分数
关于OJ的信息还有很多,这里不再赘述。
本讲义由浙江巨硬科技有限公司旗下的巨硬教育撰写。由巨硬教育教研组全体成员参与编写。
copyright :本讲义的全部内容在 CC BY-SA 4.0-署名-相同方式共享 4.0 协议之条款下提供,附加条款亦可能应用。
所谓输入输出,就是在控制台中输入输出。什么是控制台呢?看:
这就是一个控制台。也就是我们常说的命令提示符 。一般的程序的输入输出都在这里完成。
我们从最简单的一个程序开始:Hello,World!
这道题目的唯一要求就是输出一行Hello,World!。为了让程序实现输出文本这个功能,我们需要用到下面的C语言输出语句:
但是,只有那么一条语句,程序是不可能通过编译的。完整的正确的程序如下:
1 2 3 4 5 6 #include <stdio.h> int main (void ) printf ("Hello,world!" ); return 0 ; }
上面的程序有很多大家暂时不理解的地方:我们暂时把这些当做是固定搭配来记忆,以后会详细解释。所以,我们总结出的C语言程序框架是:
1 2 3 4 5 6 #include <stdio.h> int main (void ) return 0 ; }
我们把程序所要执行的语句写在return 0;和{之间——正像上面的程序一样。
暂时记不住程序结构也没关系,练习的次数多了,以后自然会记住的,不要着急。
现在你学会了C语言的输出语句了吗?如果答案是肯定的,那么恭喜你,你已经成为了一名程序员,并且已经教会电脑说话了!
输出5次“Hello,World!”。
什么是变量呢?变量就是指值的大小会改变的量 。比如大家在玩游戏时人物的血量值——血量值是一直在更新的,不是恒定不变的,那么血量值就是变量。
我们也可以从数学函数的角度理解变量。如函数y = f ( x ) = a x + b y=f(x)=ax+b y = f ( x ) = a x + b x x x y y y 常量 。顾名思义,常量就是那些值一直不变的量。比如上述函数中的a a a b b b
变量和常量的概念同样适合于C语言——或者说,它适用于所有的编程语言。
由于变量和常量里面存的是数值,所以我们就需要知道有哪些类型的数值:
在C语言中,同样有对应数值类型存储的变量(常量)的类型。如下表所示:
关键字
范围
int[ − 2147483648 , 2147483648 ] [ -2147483648,2147483648] [ − 2 1 4 7 4 8 3 6 4 8 , 2 1 4 7 4 8 3 6 4 8 ]
unsigned int[ 0 , 4294967295 ] [ 0,4294967295] [ 0 , 4 2 9 4 9 6 7 2 9 5 ]
unsigned short[ 0 , 65535 ] [ 0,65535] [ 0 , 6 5 5 3 5 ]
long[ − 2147483648 , 2147483648 ] [ -2147483648,2147483648] [ − 2 1 4 7 4 8 3 6 4 8 , 2 1 4 7 4 8 3 6 4 8 ]
unsigned long[ 0 , 4294967295 ] [ 0,4294967295] [ 0 , 4 2 9 4 9 6 7 2 9 5 ]
char[ − 128 , 127 ] [ -128,127] [ − 1 2 8 , 1 2 7 ]
unsigned char[ 0 , 255 ] [0,255] [ 0 , 2 5 5 ]
float[ 3.4 x × 1 0 − 38 , 3.4 × 1 0 38 ] [ 3.4 x\times10^{-38}, 3.4 \times 10^{38}] [ 3 . 4 x × 1 0 − 3 8 , 3 . 4 × 1 0 3 8 ]
double[ 1.7 × 1 0 − 308 , 1.7 × 1 0 308 ] [1.7\times 10^{-308},1.7\times 10^{308}] [ 1 . 7 × 1 0 − 3 0 8 , 1 . 7 × 1 0 3 0 8 ]
注:本表中所提供的精度范围只适用于32 32 3 2 。
这张表格很重要。我希望你们都可以把他给记住。我们来详细地读一下这张表。里面出现了一个新词:关键字 。什么是关键字呢?关键字(也叫关键词)是一个语言的重要组成部分 ——他们非常特殊,因为他们对于语言语法的描述有至关重要的作用!
我们来看一些变量的定义语法:
我们首先写出了一个关键字int。之后是一个空格,空格后边是一个标识符 ——变量的名字。那么标识符的命名有什么样的规则呢?
标识符,通俗地讲,就是名字。我在这里讲一下标识符的命名规则:标识符可以包含英语的26个字母的大小写,也可以包含十个阿拉伯数字(但是不能是标识符的开头),也可以包括下划线(_),标识符不能是关键字,也不能拥有除上述字符之外的任何字符!!! 。
比如说,下面的这些标识符就是不合法的:
第一个标识符错在哪里呢?标识符不能是关键字 ,而int是一个关键字。
第二个标识符错在哪里呢?标识符不可以以数字开头 ,而9是一个数字。
第三个标识符错在哪里呢?标识符不可以包含其他字符 ,而@是其他字符。
我再举几个合法的标识符的例子:
C_Programming_Languageyear2018Macrohard_
第四个标识符是不是很出乎你的意料?
但是,我们通常有一套标识符的命名习惯:**标识符最好以小写字母开头,而不是其他。中间最好不要有阿拉伯数字(末尾可以),单词和单词中间最好以下划线分割——否则从第二个单词起,单词的首字母大写。**我举几个正确的例子:
hello_macrohardhelloMacrohardmacrohard365
合理的遵守标识符的命名规则有助于让你的代码更加优美。
口述C语言的标识符定义规则
我们对于一个人是否是文盲的评判标准是什么?他是否正确地能读和写 。现在,我们已经让计算机学会了写,是时候让它学会读了。
我们从一个最简单的程序开始:a+b问题
1 2 3 4 5 6 7 8 #include <stdio.h> int main (void ) int a,b; scanf ("%d%d" ,&a,&b); printf ("%d" ,a+b); return 0 ; }
上面的程序出现了一个之前从来都没有涉及到的语句:scanf语句:
上述代码的意义就是:从控制台读入两个整数,分别存放在变量a a a b b b
那么变量a a a b b b 1 1 1 2 2 2
1 scanf ("%d..." ,&?,&?,...&?);
假设我们要输入n n n a 1 , a 2 , … , a n a1,a2,\dots,an a 1 , a 2 , … , a n
1 scanf ("%d%d……%d" ,&a1,&a2,……,&an);
注意:输入整数的提示符是%d。逗号后面变量名字前面的&符号是必须的 。我举几个错误的例子:
第一个输入语句错在提示符错误 。输入整数的提示符应该是%d,而不是%D。C语言是区分大小写的 。
第二个输入语句错在变量前面没有加&符号 。目前,我们所写的一切scanf语句都是需要&的。&是取地址操作。
上面的程序中的printf语句也有了新的用法:
看出区别了吗?第一个printf语句只拥有一个参数,而第二个拥有两个!不过,我们已经学习了scanf的用法,第二条printf语句的用法也是可以望文生义的。它的作用是:输出表达式a + b a+b a + b 。
所以,对于执行两个整数的加法运算,这个程序像是天衣无缝了。但是,现实生活中,相加的两个数往往是实数,如何实现对实数的输入输出呢?
在上一节中,我们了解到:C语言中的变量(常量)的数值类型包含整型和浮点型。我在这里补充一点:浮点型变量也是可以存储整数的 。如果想要让我们的程序支持浮点加法运算,我们首先需要把变量a a a b b b
没错,那么接下来我们尝试着修改scanf语句。在上文我讲过:%d是输入输出整数的提示符,那么自然也有给小数准备的提示符,他是%f。
那么我们就可以把scanf语句修改成这样:
下面的printf语句也是一样的改法,完整的程序如下:
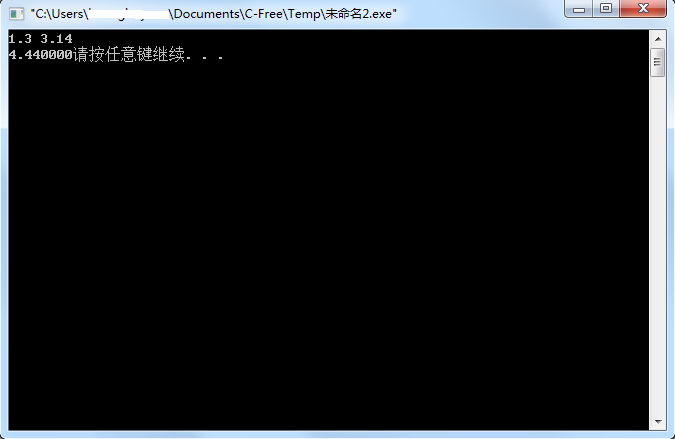
1 2 3 4 5 6 7 8 #include <stdio.h> int main (void ) float a,b; scanf ("%f%f" ,&a,&b); printf ("%f" ,a+b); return 0 ; }
程序运行效果如下所示:
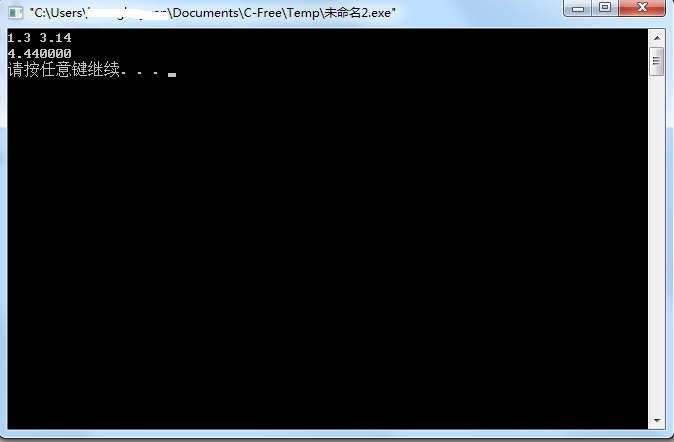
结果没有任何问题。但是这个“请按任意键继续”出现在这里是不是有点难受?我们只需要在printf语句中做一个小小的变动即可:
看到了吗?只需要加一个\n即可。在输出语句中,\n意味着输出一个回车。效果如下:
注意事项:在许多OJ中测评,有没有行尾回车都是无所谓的(也就是过滤多余的回车和空格)。但是也有一些严格的OJ,每一个空格和回车都会算的清清楚楚。所以,在做题的时候,输出一个行尾回车总是保险的。
现在你学会了输入语句了吗?恭喜你,现在你已经可以使用C语言进行简单的编程了!稍微总结一下提示符的用法:整数用%d,浮点数用%f 。
请你完成这样的一个程序:此程序从控制台读入两个实数,输出它们的乘积。
请你完成这样的一个程序:此程序从控制台读入一个整数和一个实数,输出它们的和。
空格是什么?在我们的日常交流当中,空格没有任何的意义。比如这句话:“我 喜欢 C 语言 编 程 。”虽然字与字之间有一些空格,但我们还是可以读懂的。C语言也大致如此:只要不在标识符内部出现空格,其他部分出现空格一般是无害的 。比如下面的这个程序:
1 2 3 4 5 6 #include <stdio.h> int main ( void ) printf ( "Hello,world\n" ); return 0 ; }
这个程序是完全正确的。可见,C语言编译器也和我们人一样,对空格不怎么敏感。
需要注意的是,TAB和回车的性质和空格相似,在此不再赘述。
什么是注释?我们来看一下注释的定义 :
注释,是对书籍或文章的语汇、内容、背景、引文作介绍、评议的文字。为古书注释开始于先秦时期。中国古代分得较细,分别称之为注、释、传、笺、疏、章句等。包含的内容很广。诸凡字词音义、时间地点、人物事迹、典故出处、时代背景都是注释对象。有脚注、篇末注、夹注等形式。古籍注释列在正文之中,有双行夹注和夹注。现代书籍注释列于正文当页之下,称脚注,亦称本面注;列于文章之后或列于书籍之后者称篇末注。不管采用何种方式,全书注文的编排一般要求统一,以便于读者查考。注释在教科书中应用广泛,是学生学习的重要条件。
现代学术作品中的注释一般分内容解释和来源解释两种。前者多指对文章或书籍中某一部分词句作进一步说明,但为了防止冗杂而把它放在段落之外(文末或页边)。后者一般是为了保障原作者的著作权,注明某此语句、词语、观点的来源,以便读者的查证,另一方面也是为了尊重他人的知识产权和劳动。
那么注释在程序里面有什么用呢?很显然,注释的加入可以让人们充分的理解程序的意义。比如:
1 2 3 4 5 6 #include <stdio.h> int main (void ) printf ("Hello,World!\n" ); return 0 ; }
上面的程序使用了C语言的单行注释 的语法。拥有详细注释的程序对于初学者(甚至是根本不懂C语言的人)来说是非常友好的。因为他们可以通过注释中的内容来猜测出程序的作用。
单行注释由//打头//后边就是注释的内容。需要注意的是,单行注释是不可以跨行的 。比如下面的程序就不是合法的:
1 2 3 4 5 6 7 #include <stdio.h> int main (void ) printf ("Hello,World!\n" ); Hello,World! return 0 ; }
请记住这个规则,因为在很多编程语言当中,//都是单行注释的标志。
编译器对于任何的注释内容都是不会理会 。
跨行注释在C语言中的写法:
我需要说明很重要的一点:**跨行注释是不可以嵌套的!**比如下面的程序就不是合法的:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main (void ) printf ("Hello,World!\n" ); */ return 0 ; }
我们知道,计算机的本职工作是做计算 。那么在计算机中有哪一些常用的基本运算符呢?
在日常生活中,加减乘除运算应该是使用最频繁的运算了。C语言也提供了丰富的加减乘除运算的服务。符号表如下:
运算名称
表达符号
加法
+
减法
-
乘法
*
除法
/
需要说明的是:**运算在C语言中同样存在优先级的问题。且乘除法运算的优先级比加减法大。**对于运算,我们有下面的运算规则:
先算优先级大的运算,再算优先级小的运算。总体顺序都是从左到右的。
注意:**在C语言中处理加减乘除运算时,符号两边要是都是整数,那结果就是整数如果有一个浮点数,则结果将是浮点数。**所以,这个表达式在C语言中的结果是3。但是如果是表达式或,结果就为想一想,为什么?
当然,在C语言中,你也可以给运算加上括号,以此提升运算的优先级。需要说明的是:**C语言中只有小括号一种表示优先运算的括号!但是小括号也是可以嵌套的。**比如:( 1 + ( 1 + 9 ) ) × 10 − 8 (1+(1+9))\times10-8 ( 1 + ( 1 + 9 ) ) × 1 0 − 8 [ 1 + ( 1 + 9 ) ] × 10 − 8 [1+(1+9)]\times10-8 [ 1 + ( 1 + 9 ) ] × 1 0 − 8
取模运算应该是大家从来都没有见过的。其实这个运算小学老师应该需要和大家讲——遗憾的是,取模运算一般在高等数学中才会学到。
我们先来观察一个算式:10 ÷ 3 = 3 … 1 10\div3=3\dots1 1 0 ÷ 3 = 3 … 1
还记得各个部分分别叫什么名字吗?10 10 1 0 3 3 3 3 3 3 1 1 1 余数 。我们的取模运算求的就是这个余数。比方说我们想要知道2018 2018 2 0 1 8 365 365 3 6 5 2018 m o d 365 2018\,mod\,365 2 0 1 8 m o d 3 6 5 2018%365。%在C语言中就表达了取模运算的意思。
注意:取模运算的两个运算数一定要是int型的整型变量。
取模运算的优先级和乘除法同级。
请为自己编写的一个程序加上注释,要求使用单行注释和跨行注释。
请把下面的表达式转化成C语言的表达形式:
[ 1.5 × a + ( b c ) ] × ( a m o d b ) [1.5\times a+(\frac bc)]\times(a\,mod\,b) [ 1 . 5 × a + ( c b ) ] × ( a m o d b ) 2018 ÷ 365 + 5 3 2018\div365+\frac53 2 0 1 8 ÷ 3 6 5 + 3 5
我们现在已经掌握了printf和scanf的基本使用方法:包括输入输出整型或浮点型的变量值。事实上,C语言还提供了其他的输入输出函数。
puts函数的发明可谓是一个伟大的功绩。puts函数主要用于输出一个字符串——而不是输出变量的值。而且,puts函数输出字符串的时候自动输出一个回车。这些都不是重点,重点是:puts函数比printf快
比如这个程序段:
1 printf ("Hello,Macrohard!\n" );
就可以等价于:
1 puts ("Hello,Macrohard!" );
如果大家在以后需要输出一个带回车的字符串,请使用puts来完成任务,毕竟这是一个优化的方法。
putchar是一个非常非常快速的输出函数。需要注意的是,putchar只能输出一个字符
注意:C语言里面字符串需要用一对双引号配合表达,而单个字符则使用单引号 。
这里需要解释一下什么是字符型变量。字符型变量就是存储一个字符(注意,本讲义中的字符均指西文字符,而不是中文或其他字符 )。
实际上,我们在计算机中是无法直接表示出一个字符的。所以我们需要借助ASCLL码表 来存储一个字符。现代计算机科学存储字符的思路很明确:将字符标号,然后使用这个编号来表示字符即可 。事实上,这世界上所有的主流的码表都是这样设计的。我们来看一下ASCLL码表的编码规则:
DEC(十进制)
HEX(十六进制)
CHAR(字符)
转义字符
0
00
NUL
\0
1
01
SOH
2
02
STX
3
03
ETX
4
04
EOT
5
05
ENQ
6
06
ACK
7
07
BEL
\a
8
08
BS
\b
9
09
HT
\t
10
0A
LF
\n
11
0B
VT
\v
12
0C
FF
\f
13
0D
CR
\r
14
0E
SO
15
0F
SI
16
10
DLE
17
11
DC1
18
12
DC2
19
13
DC3
20
14
DC4
21
15
NAK
22
16
SYN
23
17
ETB
24
18
CAN
25
19
EM
26
1A
SUB
27
1B
ESC
28
1C
FS
29
1D
GS
30
1E
RS
31
1F
US
32
20
space空格
33
21
!
34
22
"
35
23
#
36
24
$
37
25
%
38
26
&
39
27
’
40
28
(
41
29
)
42
2A
*
43
2B
+
44
2C
,
45
2D
-
46
2E
.
47
2F
/
48~57
30~39
0~9
58
3A
:
59
3B
;
60
3C
<
61
3D
=
62
3E
>
63
3F
?
64
40
@
65~90
41~5A
A~Z
91
5B
[
92
5C
\
``
93
5D
]
94
5E
^
95
5F
_
96
60
`
97~122
61~7A
a~z
123
7B
{
124
7C
|
125
7D
}
126
7E
~
127
7F
DEL
注:第128~255号为扩展字符(不常用)。
上表中出现了一个新的名词:转义字符 。什么是转义字符呢?转义字符可以轻松地表达那些不便表达的字符——比如我们之前学的\n。转义字符都由\打头。
我需要说明的是:在C语言内部,字符类型其实是以整数的形式存储的 。也就是说,char其实也是一种整型类型。
讲完了字符变量,也就可以讲getchar了。getchar函数的工作就是从控制台读取一个字符。比如下面的代码段:
1 printf ("ASCALL码是:%d\n" ,getchar());
这个程序简单地讲述了一下getchar的用法。请牢记getchar的用法,这个函数在未来的程序编写中将由非常巨大的作用。
请你完成这样的一个程序:此程序从控制台读入一个字符,输出它的ASCLL码。
请你完成这样的一个程序:此程序从控制台读入一个字符,请输出这个字符。
到目前为止,我们已经讲完了C语言最基础的一部分语法。通过对这些输入输出函数的合理利用,相信大家已经可以完成一些非常简单的程序了。